I have a case where I need to show only the top rows based on a setting in a table and the ordinal set.
Example dataset below shows two customers; each of the customers have a different product.
Since NumRowsToShow is “1” I only want to show one row (the top row based on ordinal) for EACH Customer.
| CustomerID | ProductID | Ordinal | NumRowsToShow |
+------------+-----------+---------+---------------+
| 1 |A |1 |1 |
| 1 |B |2 |1 |
| 1 |C |3 |1 |
| 5 |D |1 |1 |
| 5 |E |2 |1 |
| 5 |F |3 |1 |
The result set after query is run should be
| CustomerID | ProductID |
+------------+-----------+
| 1 |A |
| 5 |D |
In the same scenario if NumRowsToShow were 1 for customerID 1 and 2 for CustomerID 5 I would see something like.
| CustomerID | ProductID | Ordinal | NumRowsToShow |
+------------+-----------+---------+---------------+
| 1 |A |1 |1 |
| 1 |B |2 |1 |
| 1 |C |3 |1 |
| 5 |D |1 |2 |
| 5 |E |2 |2 |
| 5 |F |3 |2 |
The result set after query is run should be
| CustomerID | ProductID |
+------------+-----------+
| 1 |A |
| 5 |D |
| 5 |E |
How can this be done?
Including a screen cap of actual result set with highlights of what I’m trying to filter down to which may be a little helpful.

(source: harpernet.net)
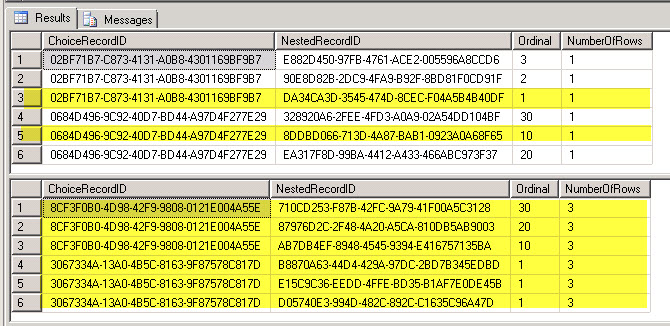{kind=link}
It feels like “cheating in the exams”:
If, as comments suggest, the
Ordinalcan have10, 20, 30values and not only1, ..., nvalues, then this will work:or even better, the:
Test in: SQL-Fiddle
Your table looks to be not normalized. The
NumRowsToShowcolumns has duplicate infomation and that can lead to update anomalies. This:could be normalized to 2 tables:
and: